-
멋쟁이 사자처럼 8주차 회고카테고리 없음 2022. 11. 3. 16:41
머신러닝 실습
이번 주는 배웠던 머신러닝에 대해 실습을 위주로 진행되었다.
데이터 전처리
정규화: 숫자 스케일의 차이가 클 때 값을 정규분포로 만들어 주거나 스케일 값을 변경해 주는 것
이상치: 이상치를 제거하거나 대체
결측치 처리

fillna, interpolate 함수를 이용
df.interpolate: 주변 값을 이용하여 결측치 처리
# limit_direction : {{'forward', 'backward', 'both'}}
# both 로 지정하면 위 아래 결측치를 모두 채워주고 나머지는 채울 방향을 설정
인코딩
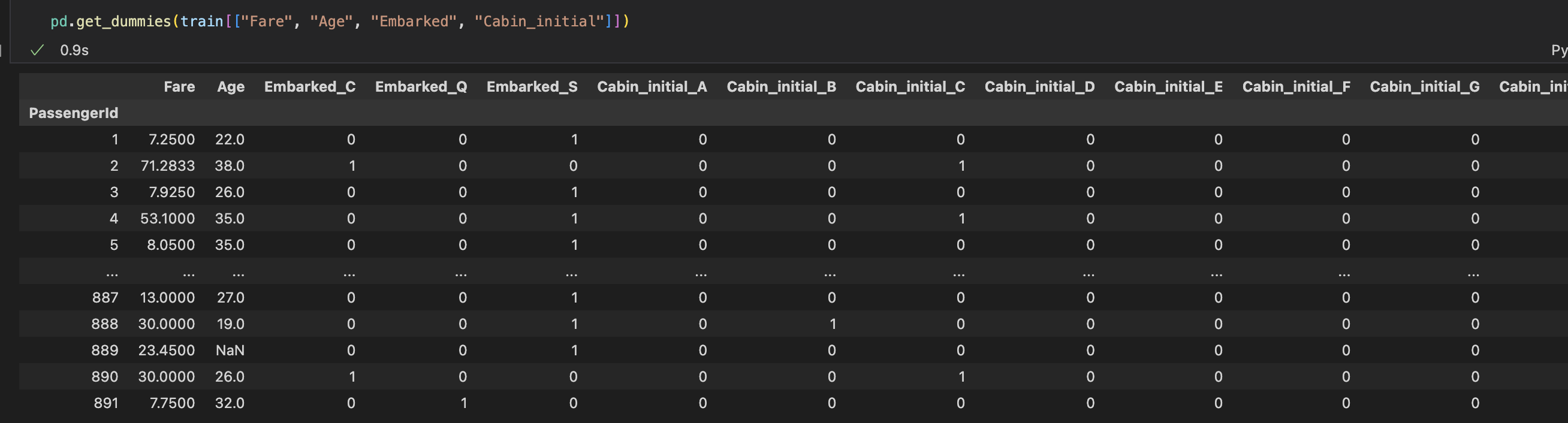
호칭, 탑승지의 위치, 문자 데이터를 수치화, 너무 범위가 큰 수치 데이터를 구간화 해서 인코딩, 모델이 학습할 때 문자를 인식 하지 못해 에러가 발생, 따라서 문자에서 숫자로 바꿔주는 인코딩이 필요하며 인코딩 방식 중 하나가 원핫인코딩이다.
순서가 있는 데이터라면 Ordinal-Encoding을 주로 사용 (순서가 없는 데이터인데 이 방식을 사용하면 의도치 않은 연산이 될 수 있음.)
순서가 없는 데이터라면 One-Hot-Encoding을 주로 사용
원핫 인코딩(바이너리 인코딩)
train["Embarked_S"] = train["Embarked"] == "S"
train["Embarked_C"] = train["Embarked"] == "C"
train["Embarked_Q"] = train["Embarked"] == "Q"
각 데이터에서 S, C, Q에 해당하는 값만 True로 반환하게 된다.
pd.get_dummies 함수를 사용하면 범주형 데이터만 원핫 인코딩하여 반환해준다. (수치형 데이터는 그대로)
머신러닝 알고리즘
# 랜덤 포레스트(회귀, 수치형)
from sklearn.ensemble import RandomForestRegressor
model = RandomForestRegressor(n_estimators = 100, random_state = 42, n_jobs = -1)
# 랜덤 포레스트(분류, 범주형)
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier(n_estimators = 110, max_depth = 6, min_samples_leaf = 6, random_state=42)
# 의사 결정 나무 (분류, 범주형)
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier(max_depth = 5, min_samples_leaf= 6, random_state=42)
교차 검증
from sklearn.model_selection import cross_val_predict
cross_val_predict(model, X_train, y_train, cv = 5, n_jobs = -1, verbose = 1)
# verbose는 로그를 찍어주는 역할

교차 검증으로 train 데이터를 분할하여 학습과 검증을 반복한다.
정확도 측정
from sklearn.metrics import accuracy_score
accuracy_score(y_train, y_valid_predict)
예측값과 실제 정답 값을 비교하여 정확도 점수를 측정
하이퍼 파라미터 튜닝
1) 그리드 서치
# 하이퍼 파라미터 범위 지정
max_depth = list(range(3, 20, 2))
max_features = [0.3, 0.5, 0.7, 0.8, 0.9]
parameters = {"max_depth":max_depth, "max_features": max_features}
# 그리드서치 함수 적용
from matplotlib.streamplot import Grid
from sklearn.model_selection import GridSearchCV
clf = GridSearchCV(model, parameters, n_jobs = -1, cv = 5)
clf.fit(X_train, y_train)
clf.best_estimator_.fit(X_train, y_train)
지정해준 범위의 파라미터 값들을 일일이 대입하여 그 중 점수가 가장 높게 나온 모델의 하이퍼 파라미터를 계산해준다.
2) 랜덤 서치
from sklearn.model_selection import RandomizedSearchCV
param_distributions = {"max_depth": np.random.randint(3,20,10)
, "max_features": np.random.uniform(0.5, 1, 10)}
clfr = RandomizedSearchCV(model, param_distributions = param_distributions, n_iter = 10, cv=5, n_jobs=-1, scoring = "accuracy", random_state = 42)
clfr.fit(X_train, y_train)
그리드 서치와 다르게 지정된 범위안에 있는 파라미터 값을 일일이 다 대입하지 않고 랜덤하게 일부만 추출하여 지정된 횟수(n_iter)만큼만 모델링을 수행하여 그 중 점수가 가장 높게 나온 모델의 하이퍼 파라미터를 계산해준다.
속도가 빠르다는 장점이 있지만 정확도가 높은 모델을 놓칠 우려가 있다.